“Why charge money for such garbage?”asked speaker KJL0 of Dialect Region 7. “Nobody in his right mind punishes a quarter-century-old dereliction.”A thirty-year-old Caucasian male with a master’s degree, KJL0 had recently recovered from a cold, which had weakened the amplitude of his nasal vowels and left him sounding stuffy. KJL0 had been guided to a soundproofed room by a group of researchers, where he was instructed to read in a “natural voice,” so as to more clearly represent his region. He was seated in front of a large screen and given headphones equipped with a microphone. The researchers retreated to an adjacent room, where they would monitor his speech and record their observations. They turned on a synthesizer that generated a low-frequency hum, which was meant to eliminate the discomfiting sound of his voice resonating in the dead room. But KJL0 nevertheless labored over each syllable, schwa, and consonant as it scrolled across the screen, and spoke with a self-conscious trill. “She wore warm fleecy woolen overalls.”He drifted in tone between recitation for the machines and conversation with the observers shrouded behind the pane of glass. “This brochure is particularly informative for a prospective buyer.”He sounded like an actor performing in a poorly rehearsed play.
KJL0 was one of 630 speakers recorded in 1986 at the facilities of Texas Instruments in Dallas, where researchers from the electronics company, Massachusetts Institute of Technology, and non-profit research institute SRI International were working to develop the first acoustic-phonetic database of American English—a definitive corpus, or collection of utterances, that would provide an empirical basis for linguistic research. Researchers sampled newspapers, novels, literary fragments, recipes, and self-help guides from an older, text-based corpus to compose 450 unique phrases, known as elicitation cues; these were meant to be short and easy to say, while prompting a comprehensive range of American English accents, dialects, and pronunciations. Researchers had originally wanted to use texts that resembled spontaneous speech, but they were hampered by their lack of time and resources. (Lines of dialogue from plays were added, however, in response to worries that the cues were sourced from written and not spoken English.) As a result, most of the cues are peculiarly artificial: “In time she presents her aristocratic husband with a coal black child,”for instance. “A sailboat may have a bone in her teeth one minute and lie becalmed the next.”Unsurprisingly, many speakers exhibited KJL0’s stilted elocution, known as “lab speech,” which was blamed on the contrived recording environment.
Funded by the United States Defense Advanced Research Projects Agency (DARPA) through its Information Science and Technology Office, this five-month recording project was designed to create a database that could be used for automatic speech recognition (ASR), which entails the conversion of speech into data that can be stored, processed, and manipulated. At the time, DARPA was eager to develop ASR for man-machine interfacing. The manifold in-house corpora used by private firms and government agencies had produced a mess of idiosyncratic models of speech. To rectify the situation and accelerate research, DARPA aimed to establish a single resource for representing “realistic” speech. This standardization of speech, and of the speaking subject, is at the foundation of today’s proliferating voice-controlled search engines, autodidactic artificial intelligence systems, and forensic speaker-recognition tools. (When such programs receive a speech signal, they parse individual sounds and compare the sequence to samples and patterns in an existing corpus, with the aid of algorithms that adjust for variables such as accent, dialect, and recording environment.)

Map of major dialect regions in the United States, from Language Files: Materials for An Introduction to Language (1982).
In order to get machines to recognize the many permutations of speech in the United States, the researchers at Texas Instruments had to construct speaker archetypes that could represent each region and demographic, and then make their characteristic dialects and patterns legible as data. The researchers employed a map from the 1982 edition of Language Files, a popular linguistics textbook published by Ohio State University, which breaks the country into five dialect regions: DR1 New England,DR2 Northern,DR3 North Midland,DR4 South Midland,and DR5 Southern.To these regions they added DR6 New York City; DR7 Western,“in which dialect boundaries are not known with any confidence”; and DR8 Army Brat,for speakers who had moved around during childhood. SRI International engineer Jared Bernstein created two shibboleths meant to demonstrate drastic differences in pronunciation between regions: “Don’t ask me to carry an oily rag like that”and “She had your dark suit in greasy wash water all year.”(Here the word “greasy” was known to easily distinguish speakers from the South [/greazy/] and from the North [/greasy/].) Researchers intended to recruit speakers who were living in each part of the country, but they didn’t have enough time or funds; they instead focused on Texas Instruments employees, who, they hoped, had maintained their regional accents.
Before being recorded, every speaker was classified by level of education, race, age, and height (earlier research had shown a correlation between size and vocal resonance). A speech pathologist identified irregularities such as vocal disorders,hearing loss,and linguistic isolation, such as “Lifetime Wisconsin.”While calling attention to exceptional demonstrations of certain dialects—one speaker was “a southern ‘lady,’”another had a “good ex-NYC-Long Is.”accent—the pathologist diagnosed peculiarities, as in the case of a speaker who had been “teased about [her]accent, and [had]tried to change her speech as a result.”These deviations were considered to be realistic, while more severe outliers—speakers with “foreign accents or other extreme speech and/or hearing abnormalities”—were judged to be unrealistic.
Researchers recorded many unrealistic speakers as “auxiliary” subjects, but ultimately omitted them from the database, which is to say that they invoked realism to justify the omission of certain populations. They constructed the typical American English speaker as white, male, educated, and, oddly, midwestern. This assumption was based in part on decades of American broadcasting, which had established the midwestern dialect of anchors like Walter Cronkiteas neutral and accent-less—what was referred to as General American or Broadcast English.1 Broadcast English eventually became an unofficial standard for measuring the correctness of everyday speech. Like its precursor in broadcasting, ASR singled out a common dialect as the optimal standard, then relegated other speaker populations to “auxiliary” status.
Of course, as a representative sampling meant to facilitate human-machine communication, a corpus is intended to provide approximations. Researchers at Texas Instruments did not seem particularly concerned with the social interactions and forms of stratification that might occur within a dialect region, and how that might shape one’s speech; in order to create a workable, stable corpus, they conceived of dialects simply as reflections of particular places at particular times, nullifying past and future migrations and social and economic shifts. They neutralized the richness of language as spoken in these regions by selecting speakers that were considered to be more useful in demonstrating dialectic variation: Men were believed to be more likely than women to use regional forms, so twice as many of them were chosen to represent each area. African Americans, labeled “Black (BLK),”were believed to speak a dialect that was isolated from the dominant regional forms, so fewer of them were included in the corpus; the same was true of “Oriental (ORN),”“Spanish American (SPN),”“American Indian (AMR),”and “Unknown (???)”speakers. Which isn’t to say that researchers had no inkling of the importance of these factors: In a report compiled during the corpus’s formation, they drily noted that race and other “macro-level relationships—dialect region, utterance speed, style, sex-linked variation—are pervasive enough to be useful in improving predictions of forms for automatic speech recognition.”
In 1990, four years after the recordings were finished, the Texas Instruments/Massachusetts Institute of Technology Acoustic-Phonetic Corpus of Continuous Speech (TIMIT) was released on CD-ROM. A wealth of audio was accompanied by exhaustively granular transcriptions of sounds. Each recording was transcribed at the level of phones, those distinctive, non-semantic units of speech that could potentially identify a New Englander (“dark” minus “r”) or a South Midlander (“wash” with “r”). The CD-ROM was distributed by the National Institute of Standards and Technology (NIST) as part of an effort to improve the processing of census data, management of broadcast frequencies, and evaluation of speaker recognition systems. TIMIT was an immediate hit. Following its release, the corpus was cited in nearly every academic paper about ASR. The United States Air Force used the corpus to help pilots in noisy cockpits verbally interface with their equipment. The Department of Defense used the corpus to develop a system that aimed to automatically identify the sex of the speaker. “If the speech signal is of high quality,” reported specialist Jesse Fussell at the 1991 International Conference on Acoustics, Speech, and Signal Processing, “it should not be difficult to build a practical system … to very accurately classify a talker as being male or female.” Some, however, quickly noted shortcomings. In a 1993 study, UCLA linguistics professor Patricia Keating found that the speech of her students, most of whom were younger than TIMIT’s sample population, deviated from the normative pronunciations suggested by the corpus—particularly in the pronunciation of “the,” which, with 2,202 instances,is TIMIT’s most common word.2 She also noted that, since TIMIT’s speakers “are mostly white and male,” the corpus would have limited use for investigating how speech patterns change depending on demographic shifts.
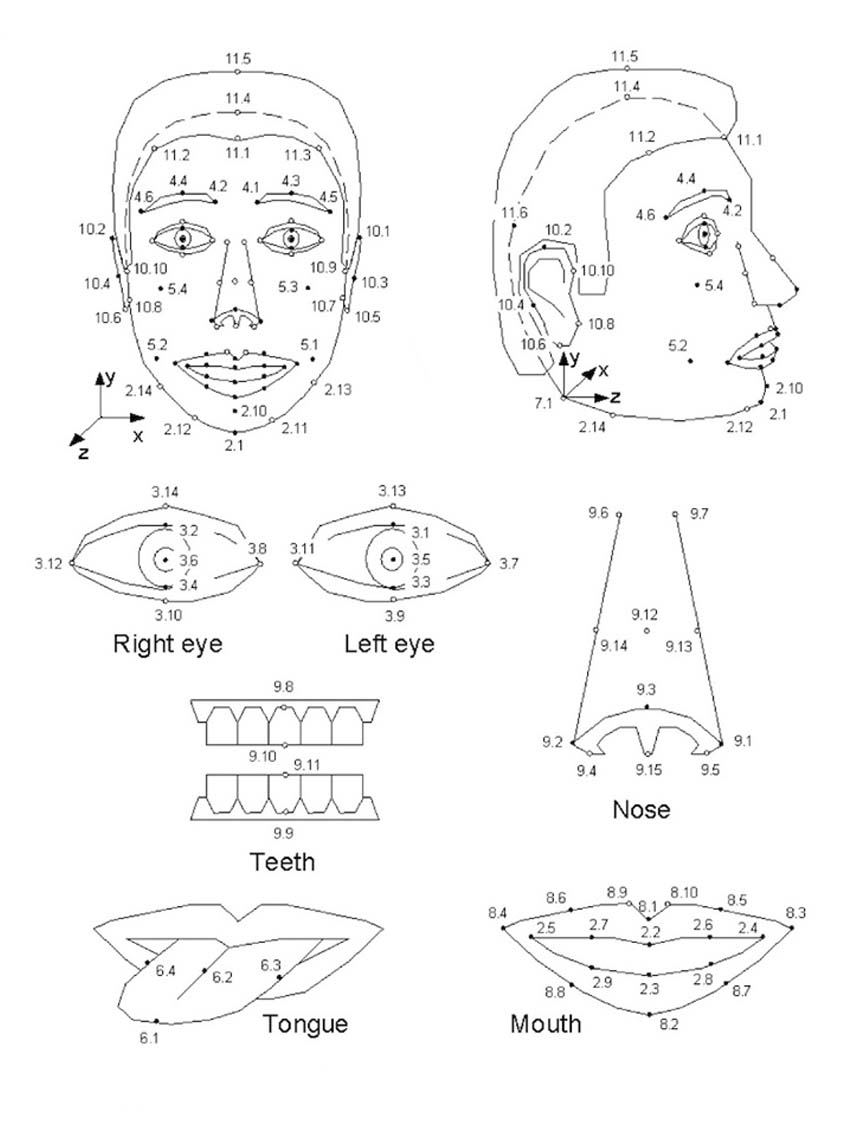
Mapping of feature points to track facial movement in speaking. Tue Lehn-Schiøler, Lars Kai Hansen, and Jan Larsen, “Mapping from Speech to Images Using Continuous State Space Models,” Lecture Notes in Computer Science 31 (2005).
Beginning in 1992, the distribution of TIMIT was taken over by University of Pennsylvania’s Linguistic Data Consortium (LDC), the leading distributor of corpora in English and foreign languages. TIMIT remains the company’s top product, and has been used in applications as disparate as prosthetics (training cochlear implants) and home protection (programming security devices to recognize specific voices). At Duke University, researchers used TIMIT to test and calibrate “phone classifiers,” computer programs that sort phones into a limited set of categories (fricatives, plosives, labials, etc.). Meanwhile, at the Technical University of Denmark, a group of engineers linked facial movements with pronunciation, connecting each phone to one of nine “visible mouth-shape related cases,” among them friction between lips and teeth, pinched mouth corners, and protruding lips. But TIMIT is most commonly used to simulate real speech in the development of algorithms like hidden Markov models, dynamic time warping, and Gaussian mixture models, which help ASR programs adjust for variations in speech sequences.
TIMIT’s ubiquity can be explained by its extensive coverage of the micro-sounds that make up all speech, and not of American speech variations, as originally intended. (Perhaps unsurprisingly, given all the rough approximations and built-in assumptions, much of the sociolinguistic metadata that informed TIMIT’s creation has since been ignored.) TIMIT is still the only fully annotated phonetic resource available to researchers in the booming field of ASR. Consequently, the corpus is likely to have been incorporated into any ASR technology that has launched in the last three decades.
TIMIT has even found its way into non-English ASR research. Because TIMIT’s phones were transcribed in the International Phonetic Alphabet, which provides a common notation system for the world’s languages, they can be “mapped” onto target languages that lack a phonetic database. In 2012, as part of Saudi Arabia’s National Plan for Science, Technology and Innovation, King Saud University researchers were developing ASR for Modern Standard Arabic; they explored the possibilities of “cross language transfer,” or the use of corpora in other languages, to help recognize speech in a target language. The researchers worked with another corpus that has a limited selection of Arabic speakers (many of whom aren’t native speakers), and used TIMIT to provide English substitutes for missing Arabic phones. They also repurposed algorithms developed with TIMIT for English, adjusting the models to suit the cadences and sequences of Arabic.
This approach significantly improved recognition rates, and has become a popular way to adapt new languages for ASR, according to Jim Glass, senior research scientist and chair of the Spoken Language Systems Group at MIT. He likens TIMIT and its resulting acoustic models to “a sourdough starter you can use to make new loaves of bread.”
In a 1942 lecture on phonology, linguist Roman Jakobson relates the story of a man cursed with the ability to identify every unique sound that reaches his ear. At first enamored of his gift, the man is soon driven to torment by the flurry of atomized sounds, each one clamoring for recognition. The articulation of a vowel seems as meaningful as the sound of saliva sloshing about his mouth. Communication, Jakobson concludes, is based not only in acoustic observations but in linguistic meaning, the production and reception of which requires compression and organization.
In the early days of ASR, analog language processors stood in for the hexed man, striving to isolate and arrange the speech signal in order to defeat the curse. Researchers turned to mathematician Claude Shannon’s theory of communication as a process in which a recipient of a string of symbols makes educated guesses about the likelihood of the next symbol. Beginning in the 1950s, they applied this model to speech, supposing that a database of relevant symbols and patterns would enable a machine to convert an audio sample into manageable segments, recognize what is being said, and meaningfully respond.3
While ASR machines would eventually incorporate databases of words and phrases—and understand, for instance, that the word “lion” is more likely to be followed by “roars” than by “bicycle”—the first machine to recognize speech focused entirely on isolated digits. Unveiled by Bell Labs in 1952, AUDREY (short for Automatic Digit Recognition) distinguished between digits ranging from zero to nine, read aloud by a single speaker. The machine, which occupied a six-foot-high nest of unruly cables, hummed and pulsed fitfully for hours, even days, as it worked to match a recorded utterance with a sample—at which point a light bulb corresponding to the spoken digit would glow. Researchers were inspired by AUDREY’s success, even while recognizing the difficulty of getting a computer to solve the putatively simple problem of distinguishing between “ice cream” and “I scream.” (Bernstein, of SRI International, told me that these techniques were “dumb,” which is to say they were “simple, but extremely efficient.”)
In the 1960s, linguists began to utilize computers’ newfound storage capacities to process large volumes of samples and develop a more nuanced understanding of speech. In the nascent field of corpus linguistics, researchers collected vast swathes of printed materials in order to train machines to parse large bodies of literature and identify the grammatical function of each word; determine consistent terms associated with genres; and survey mass market publications to demonstrate that certain words were falling out of usage or assuming new meanings. In 1964, Henry Kučera and W. Nelson Francis published A Standard Corpus of Present-Day Edited American English, also known as the Brown Corpus, which could be read by computers. The Brown Corpus included five hundred samples that comprised more than one million words (all from prose printed in the United States in 1961), and served as a source for TIMIT’s elicitation cues.
Like TIMIT, the Brown Corpus was ambitious in scope but profoundly limited by time and resources. It was constructed somewhat haphazardly, drawing from newspapers, textbooks, men’s health magazines, and pulp novels, among them How to Own a Pool and Like It, Advances in Medical Electronics, With Gall & Honey, and Try My Sample Murders. The approach had its critics. Kučera would later recall the hostility toward computational analysis: “We were certainly not spared the label of word-counting fools, and the predictions were boldly made that we would, at best, turn into bad statisticians and intellectual mechanics.”
Nevertheless, this stockpile of texts proved enormously valuable for identifying patterns in characters, words, and sentences, as researchers identified frequencies, redundancies, and abnormalities. In 1969, the first edition of the American Heritage Dictionary referred to the Brown Corpus to establish a distinction between “standard” and “nonstandard” usages of words (the latter was subdivided into categories such as “slang,” “vulgar,” “vulgar slang,” and “informal”). The intention was to expose patterns of misuse and combat the increasing “permissiveness” of competing dictionaries, namely Webster’s Third New International Dictionary. Critics argued that such a corpus might narrow the scope of acceptable American English; nevertheless, most lexicographers and editors agreed that the corpus-based approach was the most efficient way to generate the dictionary’s list of words and find illustrative quotations.
Francis’s efforts to enforce a single standard for the English language had provoked ire before: In 1964, he established the Brown-Tougaloo Language Project (BTLP), which was modeled after English as a Second Language programs and taught standard English to recent African-American high school graduates. Although Francis conceived of the project as a way to foster integration, others worried that the program could instead “repudiate” a student’s dialect, as Southern University linguist San-Su Lin argued at Tougaloo during a BTLP-sponsored lecture. “We often forget,” Lin said, “that even though a student’s dialect may be nonstandard, it has great value for him.” By relegating speakers to a “non-standard” status, BTLP had, however inadvertently, created a hierarchical system bolstered by claims to realism and practicality.

Fumitada Itakura in 1970 with the Nippon Telegraph and Telephone PARCOR speech synthesizer. Courtesy of the IEEE History Center’s Engineering and Technology History Wiki.
While the Brown Corpus made it easier to analyze text, those who worked on acoustic corpora were stymied by the difficulty of storing large quantities of speech—not to mention the variability of spoken language, which made identifying fixed patterns extremely difficult. The government, which funded much of the early ASR research, got impatient. One major critic was John Pierce, vice president for research at Bell Labs and head of the Automatic Language Processing Advisory Committee (ALPAC), which had been established by the government to monitor research. In 1969, Pierce published a scathing report called “Whither Speech Recognition?” in the Journal of the Acoustical Society of America. He lambasted Bell Labs researchers, who, in accordance with Shannon’s theory, were attempting to model continuous speech as a series of individual segments. Pierce opposed the very notion that one could recognize natural speech by dissecting a series of discrete sounds and word sequences. “People recognize utterances, not because they hear the phonetic features or the words distinctly, but because they have a general sense of what a conversation is about and are able to guess what has been said,” he argued. He accused ASR researchers of being blinded by “glamor” and “deceit,” which he connected to excessive funding. That year, the government curbed its support for the Bell Labs program, which had been one of the meccas of ASR.
The work continued, however fitfully, thanks to visiting researchers, who were excluded from the ban on funding. In 1973, Japanese engineer Fumitada Itakura was brought on to develop a vocoder that could match a recording to a speech sample regardless of differences in duration or rate of speech, a problem that had previously thwarted ASR machines.4 Itakura’s efforts were so successful that in 1974 funding for Bell Labs was restored.
In the following years, Itakura and others demonstrated the effectiveness of statistical algorithms for ASR, as advances in digital programming, storage, and maintenance of data bolstered the process of assembling corpora. In 1982, researchers put together the first standardized database of recordings of digits, TIDIGITS, an important precursor to TIMIT that featured speakers representing twenty-one regional dialects; what followed was a proliferation of so-called digit recognizers, which used bipolar scales (from negative ten to plus ten) to quantify certain nuances of speech, such as Brassy/Reedy, Busy/Idle, and Insipid/Resonant.
As engineers amassed pronunciations of digits—which were prioritized because they were easy to catalogue and useful—ASR researchers rushed to build digit recognizers, using dynamic time warping to expand or contract phoneme samples in order to match incoming speech. Similarly, researchers made progress dealing with difficulties posed by coarticulation, or the tendency of speech sounds to blend with one another, by using Markov models to predict the ways in which speech sounds might mingle. The success of statistical methods had a resounding effect within the ASR community. Skeptics, who previously asserted, per Pierce, that “the brain does not deal in probabilities,” came to embrace the models they had denounced.
As accuracy improved, ASR technologies took on slightly more advanced vocabularies. For instance, the task-based Put That There machine could recognize speech in the domain of geography (“the Caribbean,”“south of Jamaica”) and naval resources (“green freighter,”“magenta trawler”). But any speech outside of this highly specific domain was unrecognizable. It became clear that to move beyond these “microworlds,” as researchers called them, would require a comprehensive corpus.
The irreducible singularity of each human voice makes it fodder for digital assistants and cockpit interfaces, but also an enticing tool for securing and controlling populations. The voice may be law enforcement’s ideal metric for identifying suspected criminals. Whether ASR meets the standards of evidence for criminal investigations remains a question; nevertheless, researchers and private practitioners periodically claim to have solved the puzzle presented by the full spectrum of human voices, resulting in waves of scientific and legal controversy.

Caption and diagram from “The Thousand Ears of Soundprints,” by Frank A. Tinker, in the June 1968 issue of Popular Mechanics (vol. 129, no. 6).
The prospect of identifying criminals through machine-assisted analysis of voice recordings gained widespread public attention soon after the Watts Rebellion devastated Los Angeles in 1965. On December 7, a CBS television correspondent interviewed a young man who, with his face obscured, described his role in setting fire to the neighborhood’s Thrifty Drug Store. “I hurled a firebomb through the front window ... and the cry in the streets was ‘burn, baby, burn!’” he said. The young man explained that, weeks after the riots, he had been stopped and interrogated by police. “I asked them what was I going to be booked on, and they couldn’t tell me.” He spent the next month in jail awaiting trial, but when the day finally arrived, the case was thrown out due to insufficient evidence.

Photo and caption from LIFE, July 21, 1967 (vol. 63, no. 3).
Soon after the CBS documentary aired, police obtained a tape of the program. Searching for the unidentified speaker, the police located eighteen-year-old Edward Lee King, whom they brought into custody on a narcotics charge. On January 28, 1966, police recorded their interrogation of King, then called on Lawrence Kersta, president and founder of Voiceprint Laboratories, to match the resulting audio to the original CBS program.
If a machine can determine what is being said, Kersta wondered, couldn’t it also determine who is speaking? He began to confront this question as a Bell Labs engineer during WWII, when the government wanted to develop spectrographic technology for military use.5 After the war, Kersta continued to work independently; in 1962, he announced the birth of the voiceprint, a method for visualizing the voice by transcribing speech onto paper via spectrograph. He claimed that the voiceprint, which breaks down speech into frequency, time, and intensity in order to match voices to recordings, was 99 percent accurate.
Kersta established Voiceprint Laboratories in Somerville, New Jersey, where students learned the basics of spectrographic analysis and got licensed as “voiceprint examiners.” The eclectic two-week courses certified practitioners not only in forensics but in psychiatry, schizophrenic therapy, and cleft palate repair. Among Kersta’s students were detectives from the Michigan State Police Department, which subsequently purchased a $14,500 voiceprint machine for the East Lansing headquarters. Detectives festooned the walls of their brand new Voiceprint Identification Unit with spectrograms. A Michigan paper warned locals: “Voice Can ‘Squeal’ On You.”6
In King’s trial, Kersta testified that the voiceprint had the scientific infallibility of the fingerprint. Pinpointing the sound “ga,” he linked the CBS recording to King’s police interview, and King was convicted of arson. In the ensuing months, LIFE published a grainy image of King with the caption, “The sound ‘ga’ helps make a conviction.” Magazines like Popular Mechanics and Popular Science celebrated Kersta and the voiceprint, describing the spectrum of possible applications: blocking obscene callers, deterring pesky telemarketers, and identifying suspects’ voices. Even a mouth full of marbles could not deter the voiceprint, Lawrence argued in one interview. “Disguise your voice in any way,” he quipped. "We’ll still pick you up.”

Edward Lee King discussing his voiceprints with his lawyer. Photo from Jet, February 9, 1967 (vol. 31, no. 18).
Two years later, King’s attorney appealed the conviction on the basis that the voiceprints had been erroneously considered as scientific evidence. The Court of Appeals of California reviewed the opinions of experts in fields ranging from phonetics and linguistics to anatomy and physics. All roundly condemned Kersta’s methods. Perhaps the most vehement among them was UCLA phoneticist Peter Ladefoged, who had written a paper the previous year that called voiceprints a “complex of transcendental, semi-mystical beliefs surrounding, and tending to endure with an esoteric and scientific value, the manipulation of snipped-up spectrograms.” The court reversed King’s conviction. While accurate results could be achieved in a lab, experts stated, those conditions had no bearing on the real world.

Oscar Tosi comparing voiceprints of Paul McCartney’s voice and a telephone recording in October 1969. Confirming that the voices were one and the same, Tosi debunked widespread rumors that McCartney had died.
Alarmed by the appeals, Michigan’s Voiceprint Identification Unit arranged for its voiceprint methods to be reviewed. Conveniently, the ideal candidate for such a study was nearby: Oscar Tosi, Michigan State University professor of audiology, speech sciences, and physics. He was already renowned for his research efforts, which included a study of the effects of Parkinson’s Disease on speech patterns, as well as a government-funded study of the effects of LSD on combat-readiness. Tosi, who felt that voiceprints were promising but ultimately unreliable, was prompted by the police department (and funded by a $300,000 grant from the Department of Justice) to embark on a study that would last two and a half years.
Tosi began in 1968 by examining Kersta’s dubious 99 percent accuracy rate, which referred to examiners’ ability to match spectrograms within a randomized set in Kersta’s original trials. The examiners in the trials cited, Tosi found, were not experts, but rapidly trained amateurs; eight were high-school girls earning extra credit. Moreover, the spectrograms were produced by a diverse range of speakers with differing demographic traits, so they were quite easy to distinguish from one another. Tosi held his own trials, training voice examiners and challenging them to identify or eliminate voices from a more homogenous set: 250 white male students, all of whom possessed a General American accent without defects. He found that the accuracy rate was still quite high.
The claims became more concrete as Tosi and his associates amassed and examined more than 35,000 spectrograms. In 1969, Tosi felt confident enough to use the spectrograph to prove that, contrary to rumor, Paul McCartney was indeed still alive. Academics revised their opinions. Ladefoged even applauded the tests as “an excellent piece of work, well-designed and carried out with true scientific objectivity.”7 All the while, Tosi distinguished his work from Kersta’s by substituting for “voiceprints” the more legitimate sounding “aural-spectrographic method.” When students continued to confuse the term, Tosi became irate. “He called me a stupid shit,” one student recalled almost fondly. “Actually, because of his heavy Italian accent, he called me e-stupid a-sheet.”
By 1972, Tosi and other voice examiners had convinced at least twenty-five courts in approximately twenty jurisdictions to admit voiceprint identifications into evidence. To Tosi, the positive reception illustrated his method’s validity; for others, it illustrated the lack of standards for governing such evidence. Following a standard established in 1923 in Frye v. United States, courts considered evidence admissible if the methods by which it was obtained were generally accepted by the relevant scientific community. But in the case of spectrographic methods, the scientific community was a highly eccentric group that tended to validate one another’s work without close scrutiny. They dazzled courts with their stockpile of voices, citing in their testimony figures like “50,000 spectrograms” and “94 percent accuracy.”
During the following decade, courts throughout the country struggled to distinguish the amateurs from the experts. After a lower court in Arizona allowed a defendant to present spectrographic analysis of his own voice as expert testimony, the state’s Supreme Court attempted to define the relevant scientific community.8 The court only got as specific as “disinterested and impartial experts in many fields, possibly including acoustical engineering, acoustics, communications electronics, linguistics, phonetics, physics, and speech communications.” The definition of general acceptance also proved difficult. Affirming the conviction of twin sisters for wire fraud in a case that relied on voice examination, an appellate court in Ohio held that “neither infallibility nor unanimity is a precondition for general acceptance of scientific evidence under Frye.”
In the 1993 case Daubert v. Merrell Dow, the Supreme Court superseded the Frye standard’s “general acceptance” test, requiring judges to more closely scrutinize the methodologies underlying scientific testimony. In addition to the criterion of “widespread acceptance within a relevant scientific community,” the court ruled that judges must consider “whether the theory or technique in question can be (and has been) tested, whether it has been subjected to peer review and publication, [and] its known or potential error rate and the existence and maintenance of standards controlling its operation.”
The use of voiceprints and spectrographic methods in courts quickly declined. (Voiceprints have only been accepted by a court once since 1995.) While the Daubert ruling certainly played a large role, there were other factors: namely, the emergence of more promising mathematical and probabilistic methods due to advances in computing. The past two decades have seen most forensic labs in the United States outfitted with some form of Forensic Automatic Speaker Recognition (FASR). Like ASR, FASR uses computer programs to measure the physical parameters of speech in order to extract distinctive features like dialect, cadence, or speech abnormalities. The forensic component is the creation of speaker profiles, which are meant to determine the speaker’s physiological traits as well as physical surroundings. FASR research often begins with TIMIT and its phone library, and explores, for example, whether fricative or nasal phones are more useful for identifying unknown voices.
FASR is occasionally dismissed as the digital equivalent of voiceprints. Obviously, today’s computers can process speech with a speed and thoroughness that improves on Tosi’s spectrogram library, and algorithms may be more objective than even the most sensitive voiceprint examiner. But the task of determining the reliability of FASR, especially for judges and jurors, is daunting. Dubious certificates of expertise and FASR tools have proliferated. Companies often boast of champion programs and high scores in annual NIST-coordinated competitions, despite the organization’s frequent and explicit warnings that the results should not have any bearing on courtroom decisions and competitors cannot publicly claim to “win.”

Tom Owen. Photo by Sarah Rice.
Lawyers are not always deterred by the fact that evidence based on speech recognition rarely passes the test of admissibility in court. In 2013, the Florida prosecutors in the trial of George Zimmerman, who shot Trayvon Martin to death, summoned Tom Owen, a forensic voice analyst and former audio engineer, to identify the screaming voice in the 911 call made by a neighbor as the gun was fired. During the admissibility hearing, Owen used the Easy Voice Biometrics system—which, he noted, performed “fairly well” in the NIST evaluations—to compare the screams to an earlier call from Zimmerman to law enforcement. He determined that the screams did not match Zimmerman’s voice and, by process of elimination, had to be Martin’s.
Owen’s work raised suspicion. He had cleaned up the recording, which was fairly muddled, before playing it for the jury. (In 2003, he noted in Popular Science that his forensic alterations were hardly different from removing the pops and hisses from a Dionne Warwick album.) Owen first isolated seven seconds of screaming, which the software, according to court documents, rejected for being too short; compensating for the dearth of material, he looped the sample twice. Owen also manipulated the sample of Zimmerman speaking, raising the pitch to match the screams—an alteration that the defense’s experts described as “ridiculous” and “disturbing.” George Doddington, who had worked on TIMIT at Texas Instruments, argued that a scream erases the distinctive features of the speech signal. Peter French, another expert, went further: “Even if we had a sample of someone screaming repeatedly, in the same manner, for hours, it wouldn’t be enough information.” The judge ruled the evidence inadmissible, stating that the scientific methodologies and techniques were “not sufficiently established and not generally accepted in the scientific community.”
Following a discussion of Florida v. Zimmerman at the 2014 Odyssey Conference on Speaker Recognition, researchers decided that any future developments in FASR should emphasize the Daubert standard, as well as methodological transparency and faithfulness to actual forensic scenarios. Prohibited by ethical guidelines from inducing relevant states like anger and fear in subjects, however, FASR researchers have turned to corpora of “acted” or “posed” speech, such as LDC’s Emotional Prosody and Speech Transcripts. (Others have turned to corpora that include, for example, recordings from the Great American Scream Machine at Six Flags Great Adventure.) At NIST, researchers eschewed emotion altogether in order to focus on the problem of noisy channels, which is also crucial to forensic scenarios.
Despite the Zimmerman ruling and the Odyssey conference, the pursuit of questionable applications of FASR continues. Some companies claim to already be able to model all linguistic scenarios. European biometrics company Agnitio, which is steadily gaining clients in the United States, claims that a product called BATVOX can achieve “certainty of identification” and produce courtroom-ready documents. BATVOX is programmed with a corpus organized by standard criteria such as age and gender, but focuses on the physiological dimensions of the vocal tract. Agnitio describes BATVOX as being “language and speech independent and thus able to deliver results irrespective of the language or accent used by the speaker.” Technologies like BATVOX promise to usher us into what John Pierce might call the “euphoric stage” of FASR, in which questionable reliability is obscured by the excitement for new methods and tools. Nominal successes have sparked widespread, perhaps premature, adoption of the kinds of algorithms at work in BATVOX. “I-vectors perform well,” said Doddington, referring to one such algorithm, during his testimony in Florida v. Zimmerman. “Then suddenly everybody’s got I-vectors.”

Still from a 2010 Shabab propaganda video, Inspire the Believers. Courtesy of Christopher Anzalone.
In 2015, at a federal district court in Brooklyn, independent forensic consultant Geoffrey Stewart Morrison testified against the use of BATVOX to identify a suspect in a terrorism trial. After being apprehended in Djibouti and, in 2012, turned over to the United States, Ali Yasin Ahmed, Mahdi Hashi, and Mohamed Yusuf were charged with conspiring to provide material support to the Shabab, the Somali militant group. Evidence against Yusuf included intercepted phone calls and a propaganda video titled Inspire the Believers. Prosecutors notified the defense that they had hired Jonas Lindh, an independent researcher and engineer, to testify, and that they intended to use the phone calls to identify Yusuf’s voice in the propaganda video. In a written report submitted to the defense before testifying, Lindh referred to a standard scale for the strength of evidence and indicated that Yusuf was very likely to be the speaker in the video. However, the defense did not find Lindh’s methodology to be entirely transparent, and, with Morrison’s guidance, invoked the Daubert standard and moved to block Lindh’s testimony.

Advertising image for Agnitio’s BATVOX voice biometrics tool.
Morrison criticized several aspects of Lindh’s work, but one particularly salient point concerned the selection of speech corpora, or “relevant speaker population.” A forensic scientist should not only observe the similar features between two voices, Morrison advised, but also determine whether those features are typical of the relevant speaker population; therefore, the selection of an appropriate corpus is crucial. Morrison made this point by invoking the typical Boston accent, in which “car” is pronounced as “cah.”This feature seems unique in relation to a relevant population of speakers across the country. If the corpus is limited to Boston, however, then the feature is hardly useful for isolating and identifying a speaker.
Lindh had begun by comparing the recording of the subject, a naturalized Swedish citizen originally from Somalia, to BATVOX’S pre-programmed Swedish corpus. (This, as Morrison stressed, was a mistake: When working with FASR, the recording should be used to determine the relevant population, not the suspect.) Less than 1 percent of the speech included is Somali-accented. In this context, Yusuf’s speech and that of the speaker in the video sound similarly unique. Despite the NIST’s dictates, Lindh defended himself by pointing to BATVOX’s exceptional performance in the annual evaluations. After the completion of the Daubert hearing, but before the admissibility of evidence had been decided by the judge, Yusuf negotiated a guilty plea and was sentenced to eleven years in prison.
I asked Morrison, who works at the University of Alberta's phonetics laboratory and used to act as scientific counsel to Interpol, what definitive information FASR can actually provide about a speaker. He told me that sales brochures are prone to exaggerated claims that no professional practitioner takes seriously. “Look, you can probably tell how tall I am from my voice alone. But can you tell how fat I am?”
That said, given how accustomed we're becoming to voice recognition, and the amount of money being invested in Siri-esque tools for every facet of our lives, Morrison says that courts are likely to accept testimony based on FASR soon. And “once the door is opened for one case,” he cautioned, "there may be may be a surge forcing the door wide open.” Technologies like BATVOX will pervade law enforcement and the reductive representations of speakers that compose TIMIT will be conflated with real speakers in real-life scenarios. Then jurors and judges, along with the rest of us, will be left to chart what the Frye decision calls the “twilight zone” between laboratory experiment and forensic evidence.
1 During the 1950s, NBC even issued a pronunciation handbook, which claimed to be the “network standard” for American English (and lauded NBC's anchors). The handbook argued that the sort of speech that travelled across NBC’s signal was most commonly used by Americans and therefore the most readily understood.
2 According to Keating, younger speakers were drifting away from the [i], which means they pronounced “the” as “th-uh” and not “thee.”
3 For instance, as Roberto Pieraccini writes in The Voice in the Machine: Building Computers That Understand Speech (2012), a machine might receive a voiced plosive followed by a vowel with rising tones and a final weak burst of energy, and refer to its database to identify the segment as a /b/.
4 In an interview conducted by the Center for the History of Electrical Engineering of the Institute of Electrical and Electronics Engineers, Itakura attributed the versatility of his machines to the fact that they had been tested on a “worst-case” scenario: his own voice, which he described as somehow both high-pitched and husky.
5 Though Kersta was the first to put this technology into practice, Bell Labs had already explored the potential of using oscillograms (representing amplitude) and spectrograms (representing frequency) to identify voices. In a 1935 United Press interview, acoustician and pop science author E. E. Free assured the public—which had been made anxious by controversy over whether Charles Lindbergh could reliably identify the voice of Bruno Hauptmann, who was suspected of kidnapping Lindbergh's son and later executed—that there would eventually be no doubt concerning the identity of a speaker. United Press made spectacular claims for the emerging technology: “More infallible than fingerprints,” read the headline. “It will dig out an accent,” the article continued, “show up old habits of speech, and determine your nationality.”
6 This headline followed one of unit’s earliest cases, which involved a group of teenagers who had allegedly stolen a tape recorder, used it to record a litany of profanities, then dumped the evidence in a nearby river. A detective salvaged the tape, then used his spectrograph to match those watery voices with those of the suspected teens.
7 Ladefoged later reversed his opinion again. Brought in alongside Tosi to provide testimony on whether voiceprints should be admissible as evidence in the case State ex. Real Trimble v. Hedman (1971), Ladefoged rejected the Michigan professor’s claim that male voices could be used to identify female speakers. The court found the tests reliable enough to corroborate “opinions as to identification by means of ear alone”; Ladefoged wrote a letter to the President’s science advisor that urged the scientific community to review the influence of voiceprints in court, and cast doubt on whether the tests included truly challenging forensic scenarios. “What about a gang of high school dropouts,” he suggested, “with mutually confusable voices?”
8 The defendant, Alex Gortarez, had been arrested in a wiretap investigation conducted by Phoenix police, who claimed that taped recordings featured Gortarez discussing the details of a heroin distribution scheme. In order to prove his innocence, Gortarez compared a spectrogram of his own voice and one of the voice in the police recording, and highlighted the subtle differences.